$path
[1] "/home/g/R/castarter_tadadit/Telegram"Analysing Russian news via Telegram, processing them with open LLMs
datasets
russia
text-mining
telegram
Testing alternatives for investigating public discourse.
What is this about, in brief
Starting point: What if we used LLMs (commonly referred to as “AI”) to categorise Russian Telegram channels and extract information from posts?
If responses are consistent, this would be vastly more efficient than human coding; as categorisation choices are expressed in natural language, results would be easier to interpret for non-technical users, who would be able to better appreciate results and provide feedback that could be immediately implemented. As the approach relies on open LLMs (rather than ChatGPT or the likes), this would be fully replicable.
Preliminary conclusions: the whole thing is quite promising, as others have been noticing, and especially if combined with other established approaches for content analysis, can become part of reasonably efficient and effective workflows.
For R users: I’ve developed a package to streamline local operations with this specific use case in mind, see more on the package’s documentation website.
Disclaimer: if you’re interested in substantive results, rather than tentative mothodological explorations, you can safely skip this post, and wait a few more weeks for the more content-relevant follow-up.
This post points at possible solutions for two issues that are common to studies analysing different types of public discourse in Russia.
- finding textual sources that are meaningful and representative of different types of discourse, while being accessible and easy to process
- find an approach to text categorisation that is straightforward to implement for the technical user, but also easy to understand by non-technical readers, enabling engagement and substantive feedback
In contrast to my previous work, I will address the first issue by focusing on public Telegram channels (rather than text-mining websites), and the second by testing locally deployed Large Language Models (LLM), rather than plain pattern-matching or bag-of-words approaches. Both solutions are of course complementary to tried and tested approaches, and are outlined here primarily as a tentative contribution to methodological debates.
After offering some context, this post will tentatively address a substantive question, i.e. when Russian public discourse refers to territories Russia lays claim to and partially controls since its invasion of Ukraine in 2022, what does it focus on? Are military affairs central to news coverage about these regions?
In order to facilitate processing of data with these approaches, two dedicated packages for the R programming language have been developed:
telegramparser, streamlining the process of reading Telegram export files into R; at this stage, this is just a basic package collecting some convenience functions, but may be developed further.quackingllamais a more fully-featured and documented R package that facilitates interacting with open LLMs deployed locally with Ollama, efficiently caching results in a local DuckDB database (hence, the name of the package).
On Telegram as a source
Similarly to other authoritarian regimes, Russian authorities have long demonstrated a keen awareness of the role of digital media in shaping public discourse. For example, they made efforts to increase the visibility of pro-Kremlin voices on YouTube (Fedor and Fredheim 2017), even as Navalny was reaching millions denouncing government corruption on the same platform (Glazunova 2020). As Russia invaded Ukraine, pro-war Telegram channels often referred to as “Z-bloggers” or “war correspondents” (Farbman 2023) gained considerable visibility on a platform that has become increasingly prominent in Russia’s news landscape.
Telegram’s relevance may be further growing, as the functioning of services such as YouTube that have long been central to Russia’s on-line culture are being significantly degraded, and - besides TikTok - no big challengers are emerging (other US-based platforms that had a relatively significant user-base in Russia such as Facebook, Instagram, and Twitter have been banned since 2022).
Alyukov characterises the current situation as a “hybrid media system in which the government attempts to synchronise reporting across broadcast and digital media” (Alyukov 2024, 401), and points at the fact that scholars have dedicated limited attention to “autocrats’ simultaneous use of different media” (Alyukov 2024, 401), insisting on the complementary nature of different segments of the media environment.
What is worth noticing is that at this stage Telegram is effectively the main on-line space where different facets of Russian public discourse appear, including traditional media (TV, newspapers, news agencies), state officials, Z-bloggers and “war correspondents”, independent media outlets, and all sorts of public figures. All of these contents can be reached without obstacles by Russia-based users, even if not all of them are easily accessible from Western Europe.1 Telegram does limit access to some major channels based on the user’s sim card; for example, users with mobile phone registered in an EU-country wouldn’t be able to access Russian news agency “Ria Novosti” or Russian nationalist TV channel “Tsargrad”. A wide variety of channels remain however available.
For scholars interested in analysing public discourse in Russia, Telegram has an important advantage: considering how easy it is to export the entire archive of Telegram channels, it is possible to get access to a full-text archive of a wide variety of sources in a few minutes.
Although some of these channels have a substantive photo or audio-visual component, the textual part remains predominant for most of them, and even video-bloggers would mostly provide substantial hints about the content of their clips. Targeted analyses may require further attention to pictures, video, or audio contents, as was the case with this analysis of Prigozhin’s audio files. But overall, any and all big themes and trends in the Russian Runet would inevitably appear in the textual contents of major Telegram channels.
At the most basic level, exporting the textual contents of Telegram channels can be used as a speedy proxy solution in lieu of retrieving full-text contents from their original sources, as e.g. (Ptaszek, Yuskiv, and Khomych 2024) did for their analysis of Russian and Ukrainian news agencies. In order to catch big trends, the short summary of news posted by the agencies of Telegram was functionally equivalent to retrieving the original posts in full, but it was much more efficient in terms of time and/or money (no need for lenghty scraping or access to expensive services).
At present, exploring Telegram channels allows for access to more varied types of contents compared to established media. Besides variety of contents, some additional approaches are enabled by Telegram’s specificities, including references and reposts between channels, providing additional hints about network effects and news distribution dynamics. Indeed, services that rank the influence of Telegram channels in Russia (such as tgstat) do not rely exclusively on the number of subscribers to a channel, but look also at how much they are cited.
A preliminary overview of different types of Telegram channels
Here is a table providing a set of examples for Telegram channels across different types of sources that are relevant to Russian public discourse. This is not a systematic review, and just aims at providing some hints about the main types of sources that can be found on Russian-language Telegram relevant to political issues and Russia’s invasion of Ukraine.
| channel_name | earliest_post | total_posts | |
|---|---|---|---|
| Russian mainstream media | ВЕСТИ | 2015-12-14 | 144 489 |
| Первый канал. Новости | 2017-02-07 | 37 796 | |
| Russian news agency | Интерфакс | 2017-10-24 | 52 164 |
| ТАСС | 2016-06-12 | 293 416 | |
| Russian newspaper | Московский комсомолец: главное сегодня | 2016-03-02 | 74 628 |
| Коммерсантъ | 2016-03-21 | 75 830 | |
| Russian news on Telegram | Раньше всех. Ну почти. | 2018-07-05 | 193 823 |
| Readovka | 2018-03-05 | 90 607 | |
| Baza | 2018-09-13 | 34 028 | |
| Z-blogger, etc. | Kotsnews | 2017-02-01 | 49 322 |
| Операция Z: Военкоры Русской Весны | 2018-04-30 | 79 877 | |
| WarGonzo | 2017-06-07 | 22 726 | |
| Караульный Z | 2017-01-05 | 529 505 | |
| НЕЗЫГАРЬ | 2016-12-11 | 2 017 | |
| Два майора | 2022-06-26 | 61 110 | |
| Russian state official | Дмитрий Медведев | 2022-03-14 | 533 |
| Мария Захарова | 2021-05-31 | 9 259 | |
| Kadyrov_95 | 2017-05-22 | 5 259 | |
| pro-government media figure | Маргарита Симоньян | 2017-11-27 | 12 765 |
| СОЛОВЬЁВ | 2019-05-26 | 286 334 | |
| official accounts related to Russia-controlled Ukrainian territories | Администрация Херсонской области | 2022-03-18 | 25 651 |
| Владимир Сальдо | 2022-07-06 | 5 476 | |
| International media with Russian-language version | BBC News | Русская служба | 2015-11-04 | 73 847 |
| Russian independent media | Медуза — LIVE | 2016-04-06 | 118 796 |
| Телеканал Дождь | 2015-09-25 | 82 559 |
On categorising texts with open LLMs
There’s a growing literature on relying on LLMs to classify texts (e.g. Weber and Reichardt 2023; Plaza-del-Arco, Nozza, and Hovy 2023), and relatively encouraging results on how, in the right conditions, LLMs show accuracy that is reliably consistent with human coders (Bojic et al. 2025). 2. Building upon a naive previous attempt at text categorisation, this time I will rely on the structured outputs feature introduce in Ollama in December 2024, enabling more consistent parsing of results.
As an early and tentative test, I will proceed and try to establish how many of the posts that mention one of the Ukrainian regions partly controlled by Russia in a mainstream media outlet refer to military issues or to anything else, and will then parse posts that are not about military issue to extract some information about them.
I will proceed with the following steps:
- take the Telegram channel of a mainstream media outlet, in this case, “Vesti”
- extract all posts that make reference to “Kherson”, one of the Ukrainian regions partly under Russian control
- ask different LLMs to categorise these text based on a binary option, i.e. to reply either
TRUEorFALSEwhen prompted if a given text is “about military” - ask LLMs to tag posts that are not “about military”, and extract named entities such as names of individuals and locations
- check processing time with different models
- preliminarily evaluate consistency of results
About the source: Telegram Vesti
Vesti is the all-news channel of Russia’s state broadcaster. As of March 2025, its Telegram channel boasts about 170 000 subscribers. As you’d expect, most of its posts are news updates, sometimes accompanied by pictures or video clips. It is reasonable to expect that its news agenda reflects practices of the TV channel itself.
Here are some summary statistics about Vesti’s Telegram channel at the time of writing:
| Feature | Value |
|---|---|
| Earliest post | 14 December 2015 |
| Latest post | 11 March 2025 |
| Total posts | 144 439 |
| Total posts with reference to Kherson | 1 696 |
The question we want to answer at this stage is: “how many among the 1 696 posts that mention”Kherson” are about the military, and how many are not?“.
How many posts with reference to Kherson are about military affairs?
We proceed with asking this question to LLMs. There are surely more adequate techniques to get this kind of response, but for the sake of this excercise, I passed to the LLM only the most basic set of instructions:
- a system message: “You are a helpful assistant. You tag and classify Russian texts.”
- a schema set to receive a structured response, forcing the LLM to reply
TRUEorFALSEto the expression “About military”; I also allowed it to pass tags as a string, but this is ignored in the analysis for the time being (a better prompt and forcing to give results as a list rather than as a string would have been more effective). - the text of the Telegram post in full in the prompt.
I passed the very same prompt to a bunch of open LLMs, including models of different sizes by established companies active in this space (Meta, Microsoft, Google), Olmo as an example of a fully open LLM (others have only open weights), a version of Deepseek, and a few small models optimised for Russian language.3
Larger models are generally expected to be of higher quality, but slower and more demanding in terms of resources. Newer models are often more performing than older ones (in this set, Google’s gemma3 and Microsoft’s phi4-mini, are the most recent additions). Of course, a major factor determining processing speed is the hardware used for this task, in this case my own laptop, including availability of GPU and vRAM (in my case, a relatively powerful but oldish laptop, with a GPU that made 3.6 GiB of vRAM available to Ollama).
While all of these models have generic capabilities, different models excel at different tasks, as well as in their capability to interact with different languages.
| model | author | parameter |
|---|---|---|
| llama3.2 | Meta | 3b |
| phi4 | Microsoft | 14b |
| phi4-mini | Microsoft | 3.8b |
| gemma2 | 9b | |
| gemma3 | 4b | |
| olmo2 | Ai2 | 7b |
| deepseek-r1:8b | deepseek | 8b |
| mistral | Mistral | 7b |
| owl/t-lite | T-bank | 4.7b |
| akdengi/saiga-gemma2 | 5.8 | |
| lakomoor/vikhr-llama-3.2-1b-instruct:1b | 1b |
How many of these posts are about military affairs?
Looking at the result, it soon emerges that the answer to this question in many cases is not so straightforward, and that unless criteria were more clearly defined, human coders would surely have a lot of disagreement.
Indeed, unsurprisingly, different models do not reply very consistently, although larger models seemingly agree more. For example, if we limit the selection to only two of the largest models (phi4 and mistral) included in this test, we get a Krippendorf’s Alpha showing a moderate but relatively good result of inter-coder relialibility.4
phi4 and mistral have a score close to 0.8, while all others have much lower scores.5 A better definition of categorisation criteria would surely help.
| n_Units | n_Coders | Krippendorffs_Alpha |
|---|---|---|
| 1678 | 2 | 0.7687087 |
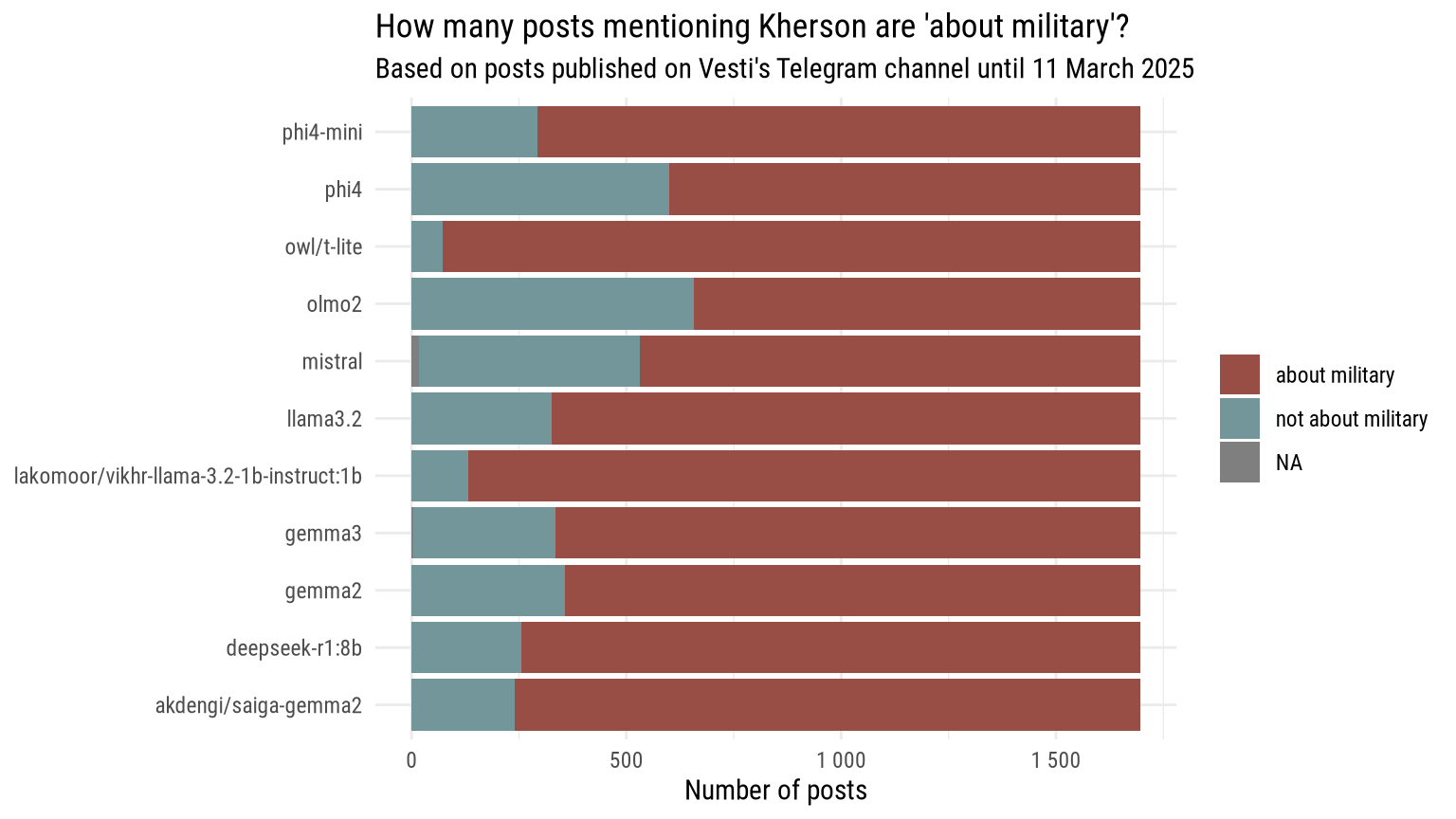
Even with such a broad and rather unsatisfying definition, it appears that according to all LLMs queried, about two thirds of posts (or more) are about military affairs.
If not about military affairs, then about what?
In conducting structured analysis, we’d review more carefully the source dataset (is Telegram’s Vesti channel really relevant?), the definition of the categorisation criteria, as well as the consistency of results (including consistency with human coding for at least part of results). As this is just a preliminary test of the workflow, I’ll proceed with processing further the dataset based on the results of the biggest among the models included (phi4).
Passing to LLMs this new list of posts (599 posts that are supposedly not about military affairs), I ask them to extract:
- name of locations
- name of individuals
- named entities
and to describe each post with:
- title
- summary
- tags
Even if in the system message I insisted that the response be in English, some LLMs effectively responded in Russian. Arguably, at least for named entities recognition, keeping the source language may well be more effective.
These are some observations after skimming through results:
- there’s some inconsistency in the response language; even more explicit clarity in the prompt may help, or perhaps it’s wiser to process data in Russian and, if needed, translate results as late as possible in the process;
- all models do a decent job of extracting information, with perhaps
phi4-miniperforming worst andllama3.2more prone to invent things (e.g. if a Russian institution is mentioned, then other institutions or officials not present in the post are also reported) - all models occasionally add some information not present in the post, e.g. if there is only a surname they tend to add a supposedly plausible first name (e.g. if only “Peskov” is mentioned, a reference to “Evgeny Peskov”, rather than “Dmitry Peskov” may be added); this is however not very common.
While not impeccable, the data seem of good-enough quality to answer some basic questions, or else hint at interesting aspects that may then be validated with other methods. For example, if it emerges that a given official is mentioned particularly often, or a location particularly prominent, this can then be systematically checked with basic word matching.
The following tables report the results for each of these responses (e.g. what title each of these LLMs gave to a given post? which individuals or entities did it identify?); by clicking on the first column on the left, you’ll see the original post on Telegram. These are shared here in order to let the reader form their own opinion on the quality of results.
These can also be downloaded as csv files (or all together in a single rds file, allowing for nested columns).
Title
Summary
Locations
Individuals
Named entities
Processing time
LLMs are notoriously demanding in terms of resources: it is possible to filter millions of posts by pattern matching in a matter of seconds, while it may well take a few seconds to process a single post with a locally deployed LLM. Of course, much depends on the hardware (and/or resources) available, but some issues of scalability emerge quite soon. The size of the model also matters significantly.
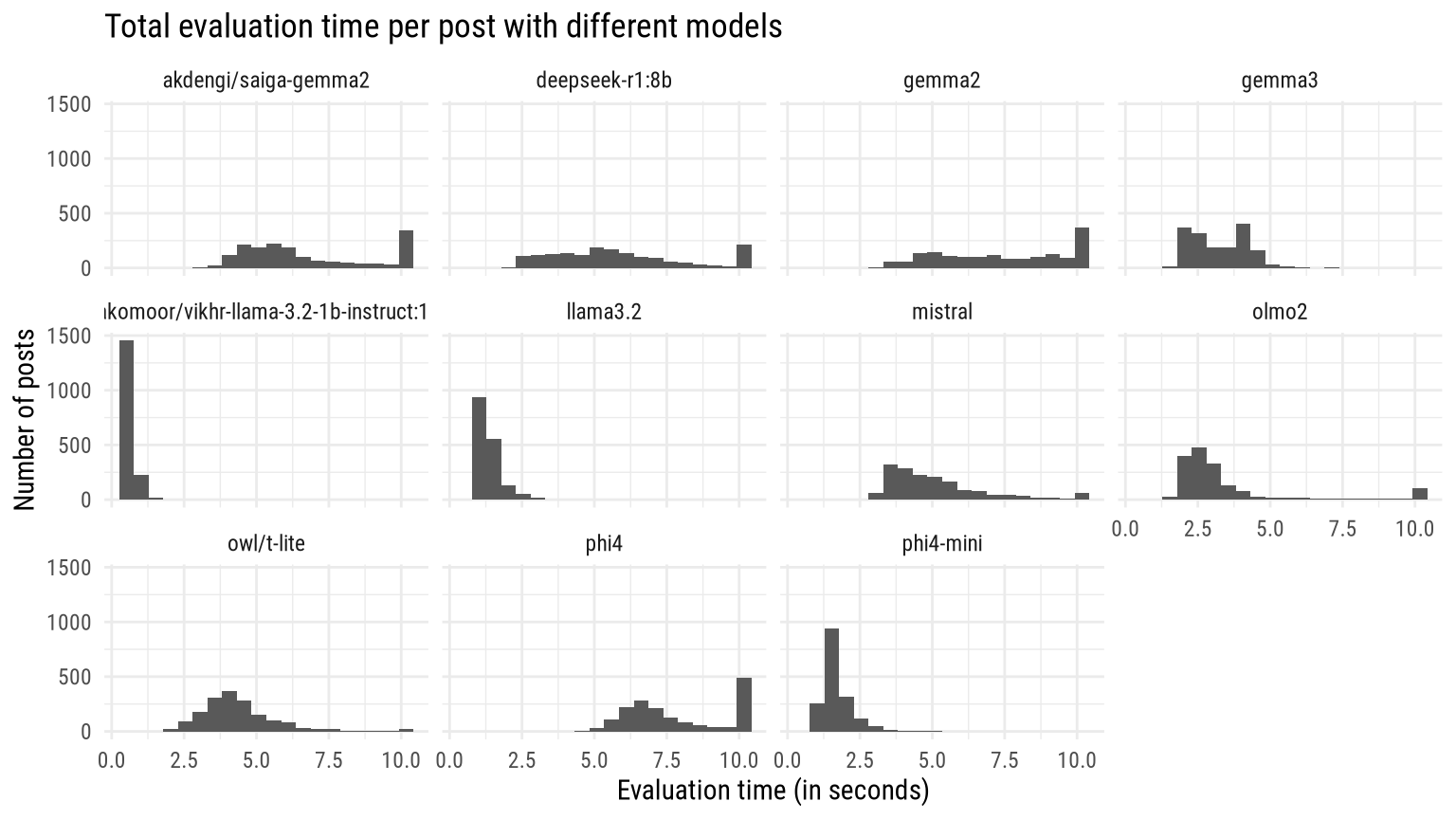
The following graphs shows how much it took to process each Telegram post in this dataset: less than a second with the smallest models, but usually about six seconds (and not infrequently more than 10 seconds) per post with the largest of those included, phi4.
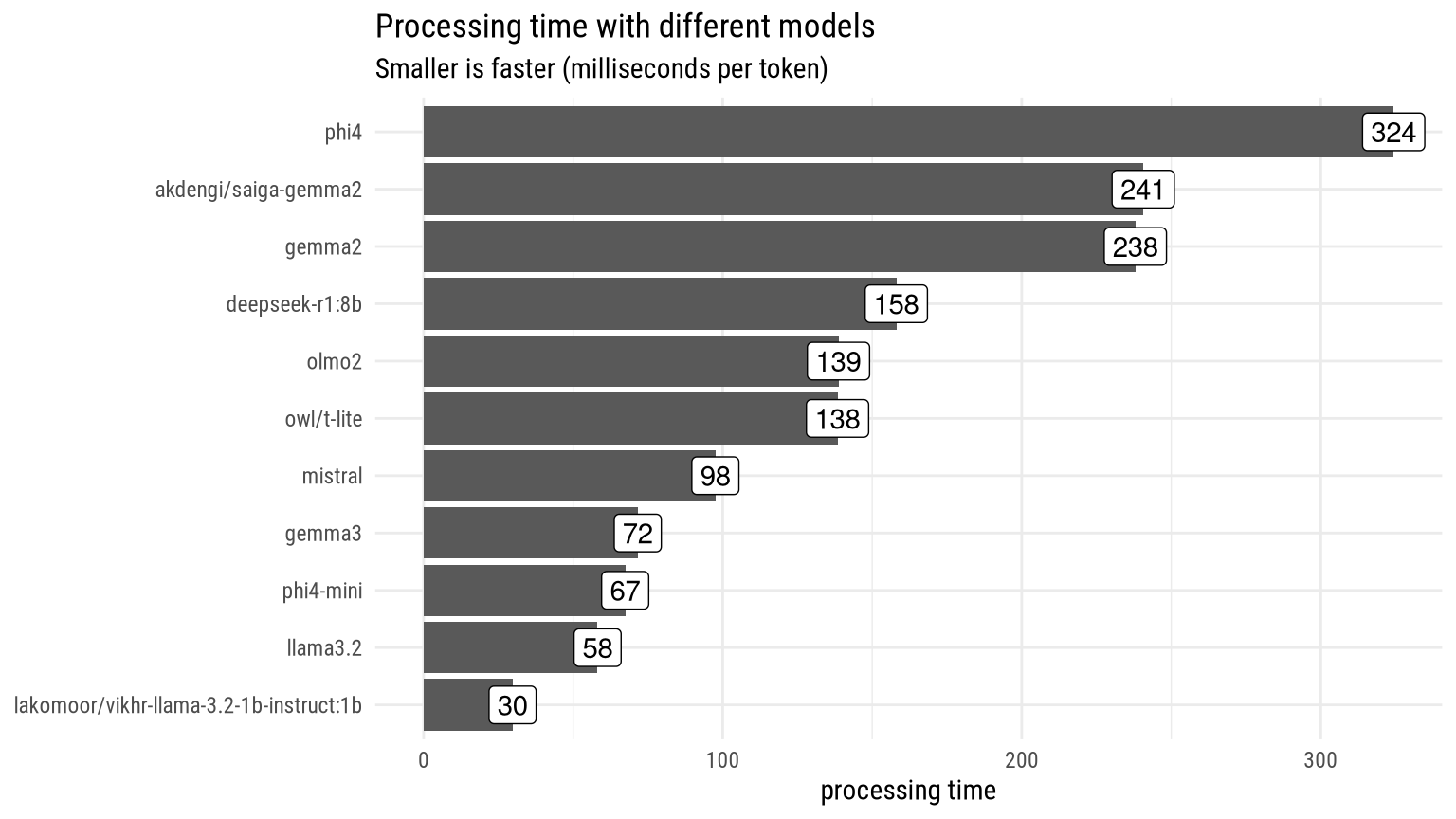
The following graphs shows average processing time per token (i.e. adjusting for the length of input), which is likely to inform the choice of model. If, for example, in terms of named entity recognition gemma3 performs just as well as phi4 but is almost 5 times faster, then there’s good reason to prefer it.
Conclusions
This post tentatively introduces a workflow for processing and categorising on-line sources with open LLMs based on two packages for the R programming language developed (and still under development) by this author , telegramparser and quackingllama.
The results presented are not inherently meaningful and have not been validated; further validation of data quality issues, including matters of inter-coder reliability, will be discussed in a dedicated post.
In terms of methods, this preliminary exploration suggests that systematic processing of contents with locally-deployed open LLMs is likely feasible, if the relevant tasks are clearly defined. Due to resource constraints, these methods will likely be used in combination with more traditional approaches for filtering contents or extracting structured information from them. Indeed, this emerges even from the approach chosen for this post: first filter contents based on simple pattern matching (i.e. if a post makes reference to “Kherson”), then refine further, then query again for details.
Even if LLMs are vastly less efficient than other computing techniques, they enable a different type of transparency compared to other approaches: indeed, as the prompts are expressed in natural human language, even non technically inclined readers will be in a position to propose alternative approaches for querying the dataset or different categorisation. Unlike traditional human-based coding, it will mostly be possible to re-process data without disproportionate human efforts. This approach can realistically be applied to replicate studies based on human coders, exploring slight variations in categorisation criteria.
Further adjustments to workflows, and considerable validation efforts, are still needed to include results in substantive research.
Credits
This project is realized with the support of the Unit for Analysis, Policy Planning, Statistics and Historical Documentation - Directorate General for Public and Cultural Diplomacy of the Italian Ministry of Foreign Affairs and International Cooperation, in accordance with Article 23 ‒ bis of the Decree of the President of the Italian Republic 18/1967.
The views expressed are solely those of the authors and do not necessarily reflect the views of the Ministry of Foreign Affairs and International Cooperation.
See project page.
References
Alyukov, Maxim. 2024. “News Reception and Authoritarian Control in a Hybrid Media System: Russian TV Viewers and the Russia-Ukraine Conflict.” Politics 44 (August): 400–419. https://doi.org/10.1177/02633957211041440.
Bojic, Ljubisa, Olga Zagovora, Asta Zelenkauskaite, Vuk Vukovic, Milan Cabarkapa, Selma Veseljević Jerkovic, and Ana Jovančevic. 2025. “Evaluating Large Language Models Against Human Annotators in Latent Content Analysis: Sentiment, Political Leaning, Emotional Intensity, and Sarcasm.” https://doi.org/10.48550/arXiv.2501.02532.
Farbman, Sam. 2023. “Telegram, ‘Milbloggers’ and the Russian State.” Survival 65 (3): 107–28. https://doi.org/10.1080/00396338.2023.2218703.
Fedor, Julie, and Rolf Fredheim. 2017. ““We Need More Clips about Putin, and Lots of Them:” Russia’s State-Commissioned Online Visual Culture.” Nationalities Papers 45 (2): 161–81. https://doi.org/10.1080/00905992.2016.1266608.
Glazunova, Sofya. 2020. “‘Four Populisms’ of Alexey Navalny: An Analysis of Russian Non-Systemic Opposition Discourse on YouTube.” Media and Communication 8 (4): 121–32. https://doi.org/10.17645/mac.v8i4.3169.
Plaza-del-Arco, Flor Miriam, Debora Nozza, and Dirk Hovy. 2023. “Leveraging Label Variation in Large Language Models for Zero-Shot Text Classification,” July. https://doi.org/10.48550/arXiv.2307.12973.
Ptaszek, Grzegorz, Bohdan Yuskiv, and Sergii Khomych. 2024. “War on Frames: Text Mining of Conflict in Russian and Ukrainian News Agency Coverage on Telegram During the Russian Invasion of Ukraine in 2022.” Media, War & Conflict 17 (1): 41–61. https://doi.org/10.1177/17506352231166327.
Weber, Maximilian, and Merle Reichardt. 2023. “Evaluation Is All You Need. Prompting Generative Large Language Models for Annotation Tasks in the Social Sciences. A Primer Using Open Models,” December. https://doi.org/10.48550/arXiv.2401.00284.
Footnotes
On 10 March 2025, access to Telegram has been suspended in Chechnya a Dagestan; it is unclear if this is just a temporary measure.↩︎
Find some more context in this previous post dedicated to text categorisation with LLMs; the implementation is much more consistent in this post.↩︎
For benchmarks of LLMs for tasks in Russian, see Ru Arena General; RuSentNE-LLM-Benchmark; Multimodal Evaluation for Russian-language Architectures (MERA); brief outline of Russian-language optimised models available for Ollama.↩︎
It should be noted, that these are all understood to be “small” models compared to those most often available to consumers through established commercial offers.↩︎
The measure known as “Krippendorff Alpha” is commonly used to evaluate inter-coder reliability. Broadly speaking, a value of 1 indicates perfect agreement among raters, a value of 0.80 or higher is generally considered acceptable, a value above 0.66 but below 0.8 indicates moderate agreement (results should be looked at with caution); a lower value indicates low agreement.↩︎