zavtra.ru_ru_2024
corpus
full corpus
Russian media
Russian language
Corpus based on the website of Russian weekly newspaper ‘Zavtra’ (in Russian, 1996-2023)
Explore or download this dataset
Explore in an interactive web interface
Links for download: compressed csv / ods / rds
Official release
Official release with DOI now available on Discuss Data:
doi:10.48320/DAE0B5B8-157F-471A-BB3C-EA24E0B2A7F7.
Giorgio Comai (2024): zavtra.ru_ru - Full text corpus based on the website of Russian weekly newspaper ‘Zavtra’ (in Russian, 1996-2023), v. 1.0, Discuss Data, doi:10.48320/DAE0B5B8-157F-471A-BB3C-EA24E0B2A7F7.
Scope of this corpus
This corpus is based on the website of Russian weekly newspaper zavtra.ru.
The structure of the website suggests a strict correspondence between the online and the printed version: the website includes an archive with a separate section dedicated to each issue of the printed version of the newspaper. Archive pages show also which contents supposedly appear on which page of the printed version. Exact correspondence, however, has not been checked.
The website also hosts additional contents, such as podcasts, which are not included in this corpus. Only contents linked from the archive page of an issue of the newspaper are included in this corpus.
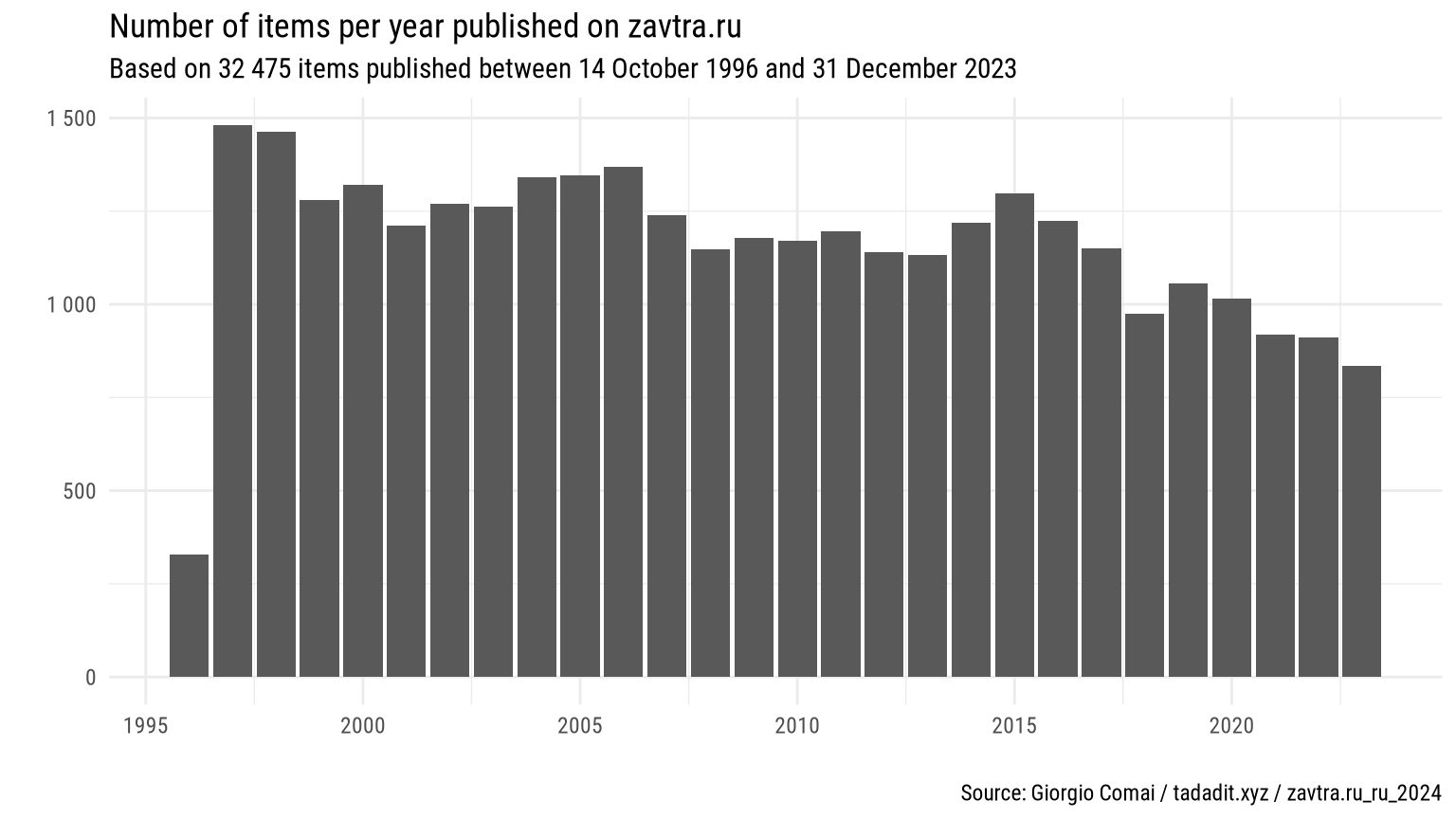
The earliest issue included in this corpus is issue 149, published on 14 October 1996. The most recent issue included in this corpus is issue 1563, published on 27 December 2023.
Summary statistics
Dataset name: zavtra.ru_ru_2024
Dataset description: all items published on zavtra.ru
Start date: 1996-10-14
End date: 2023-12-31
Total items: 32 475
Available columns: doc_id; text; title; date; datetime; author; intro; tags; issue_year; issue_month; issue_number; id; url
License: Creative Commons Attribution 4.0 International
Link for download: zavtra.ru_ru_2024
| field | present | missing | missing_share |
|---|---|---|---|
| doc_id | 32 475 | 0 | 0.0% |
| text | 32 468 | 7 | 0.0% |
| title | 32 474 | 1 | 0.0% |
| date | 32 475 | 0 | 0.0% |
| datetime | 32 475 | 0 | 0.0% |
| author | 32 459 | 16 | 0.0% |
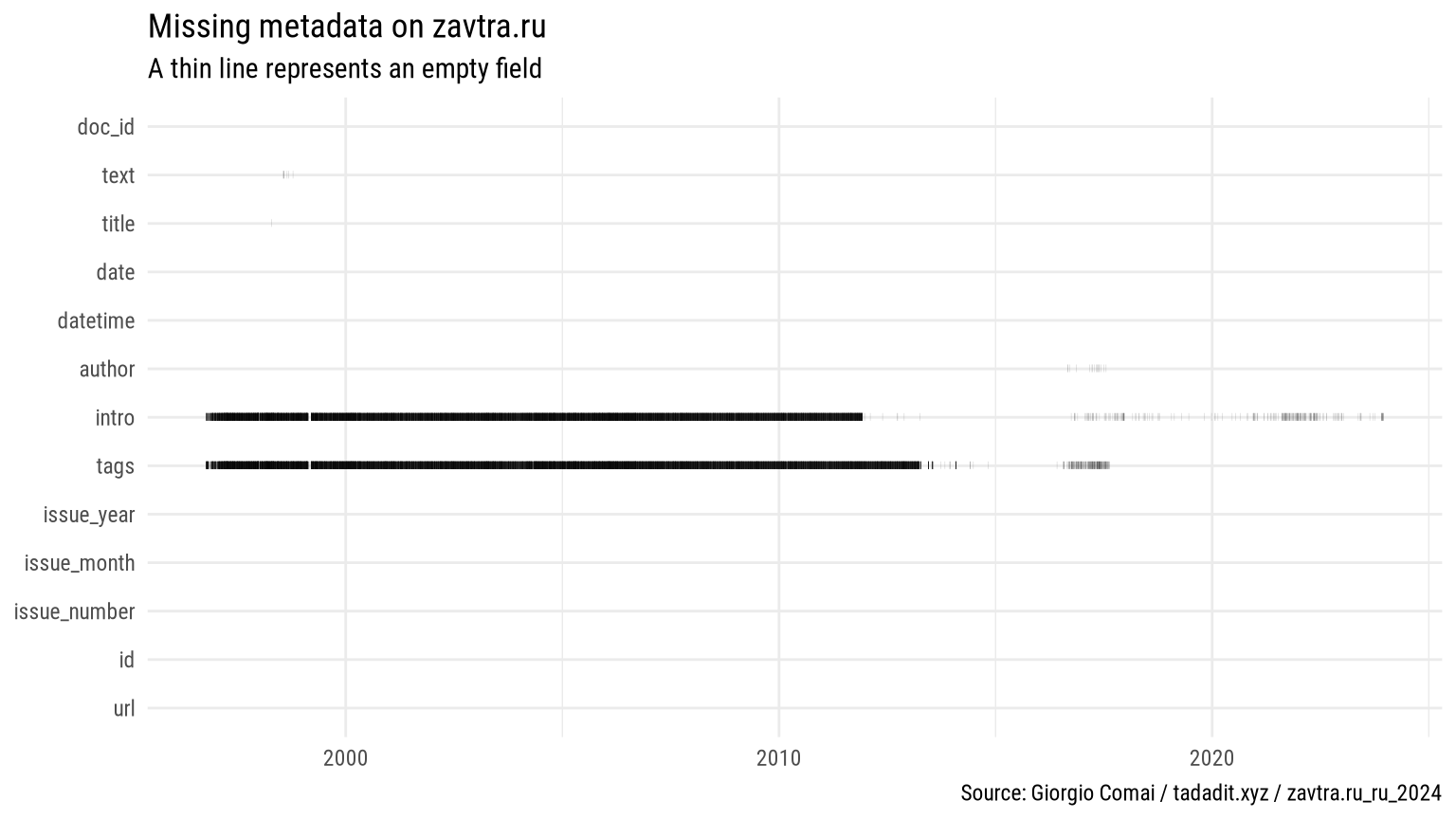
| intro | 13 479 | 18 996 | 58.5% |
| tags | 12 383 | 20 092 | 61.9% |
| issue_year | 32 475 | 0 | 0.0% |
| issue_month | 32 475 | 0 | 0.0% |
| issue_number | 32 475 | 0 | 0.0% |
| id | 32 475 | 0 | 0.0% |
| url | 32 475 | 0 | 0.0% |
Narrative explanation of how this textual corpus was built
Zavtra keeps a full archive of its publications starting from 1996. This corpus was built through a script that retrieves archive pages for each year (e.g. this for 1996), then retrieves the link to the page dedicated to each issue, and from there, extracts links to individual articles. Hence only articles attached to an issue are effectively included in the corpus.
The number of the issue in which each article supposedly appears is obtained based on the archive page where link to the given page was found (see below for potential issues).
Metadata such as author, date, and tags have been retrieved from the article page itself, based on relevant html tags. In particular:
titleis retrieved from<div>of classheader__titledateanddatetimehave been parsed from the<span>of classheader__dataauthoris retrieved from<span>of classavtor-nameintrois retrieved from<div>of classheader__anonsetagsis retrieved from<span>of classartagstextis retrieved from<div>of classarticle__content
Data quality issues
No major issues have emerged during extraction of text and metadata from the website.
As appears from the above graphs, fields such as “tags” and “intro” have been used somewhat consistently on the website only in the last decade.
Some minor issues are listed below:
- especially in articles related to earlier years, title, date of publication, and issue number may be repeated at the beginning of the article itself
- the date of publication included in such cases may be off by a few days in respect to the date of publication reported above the title
- the issue number may also be off by one, e.g. this inline text makes reference to issue 228, but is linked from the archive page of issue 227.
- a very small number of issues includes only one article
Here is an example showing all of the above issues.
Issue 227, available from the archive page related to 1998, includes only one article. This article, includes at the very beginning of its text the title, and then the following string: “15 (228) Date: 17–04–98”. This would suggest that the article was originally published on 17 April 1998 and belonged to issue 228. Yet on the very same web page, 13 April 1998 is presented as date of publication, and the article is linked from the archive page of issue 227.
Metadata in this corpus consistently rely on website metadata, hence would keep these latter points of reference, and ignore metadata included within the text itself.
As the difference is only of a few days, these issues are likely of negligibile impact for analyses looking at long term trends, but should be kept in consideration by researchers for whom exact date of publication is of the essence. Time of publication (hour and minute) should probably be disregarded for earlier years: the 3.00am time of publication reported for many articles is probably just an artifact of importing contents from previous versions of the website, which may have assumed GMT as the default time. Again, as these are the metadata currently visible online, they have been dutifully included in the published corpus, but should be looked at with caution.
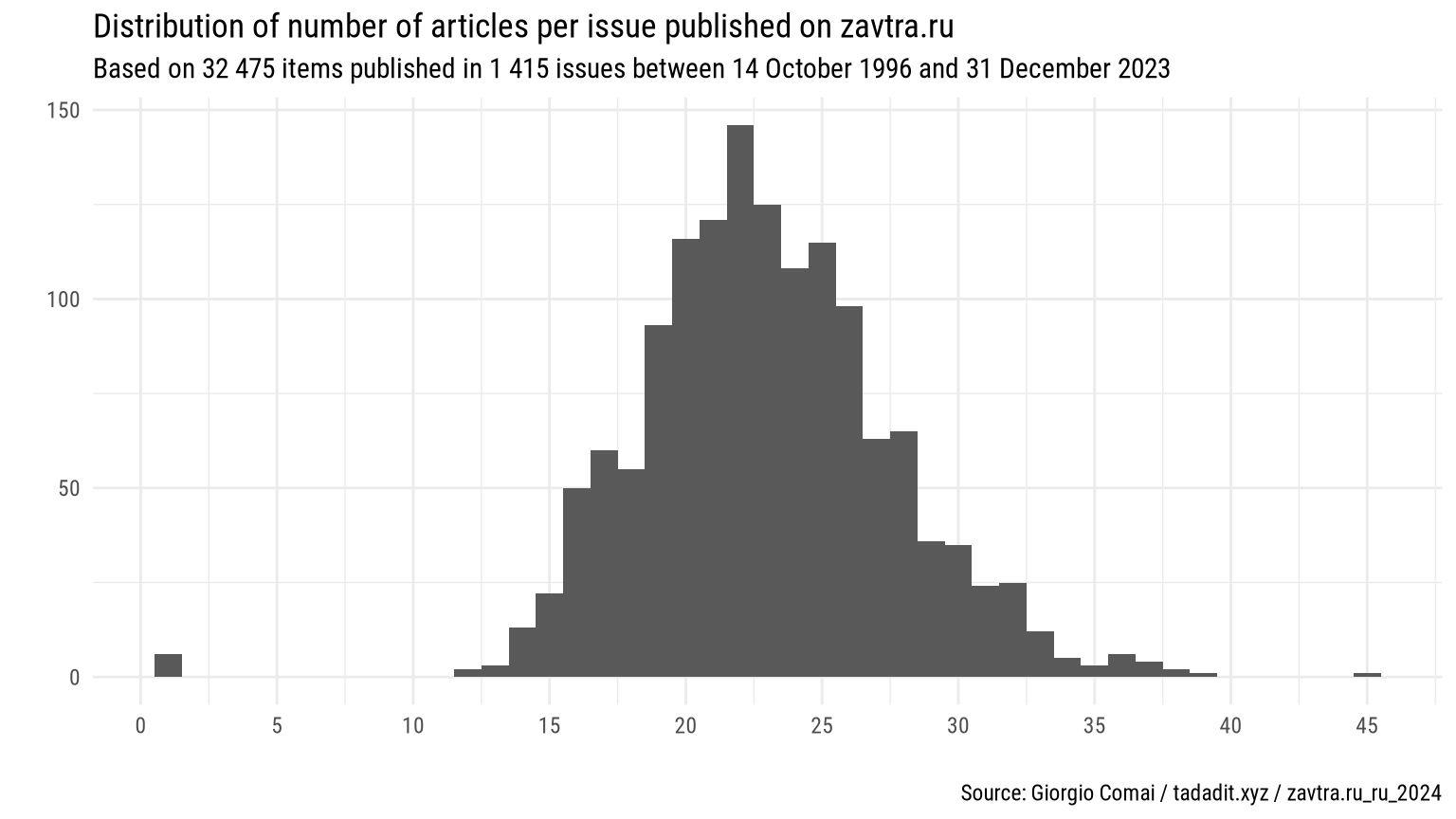
The vast majority of newspaper issues includes between 15 and 30 articles (see histogram below). In a small number of cases, as mentioned above, only one article is included in each issue. This may or may not hint at missing articles (perhaps, these were actually published as double issues, and the lone remaining article has been mis-attributed to an effectively non-existent issue). No additional checks have been conducted on these outliers.
License information
At the time contents were retrieved, the footer of zavtra.ru made clear that all contents are available under a Creative Commons license:
Все материалы сайта доступны по лицензии: Creative Commons Attribution 4.0 International
The contents of this dataset - zavtra.ru_ru_2024 - are distributed in line with this license. To the extent that it is possible, the corpus itself is also distributed by its creator, Giorgio Comai, with the same CC-BY license, as well as under the Open Data Commons Attribution license (ODC-BY).
Dataset cleaning and reordering
The following columns have been added to the original dataset before exporting:
- introduce an
id, based on the row number after reordering for issue number; this is used for reference, and does not necessarily represent order of publication - introduce a
doc_idcolumn (composed of the website base url, the language of the dataset, and theid) and set this as the first column of the dataset